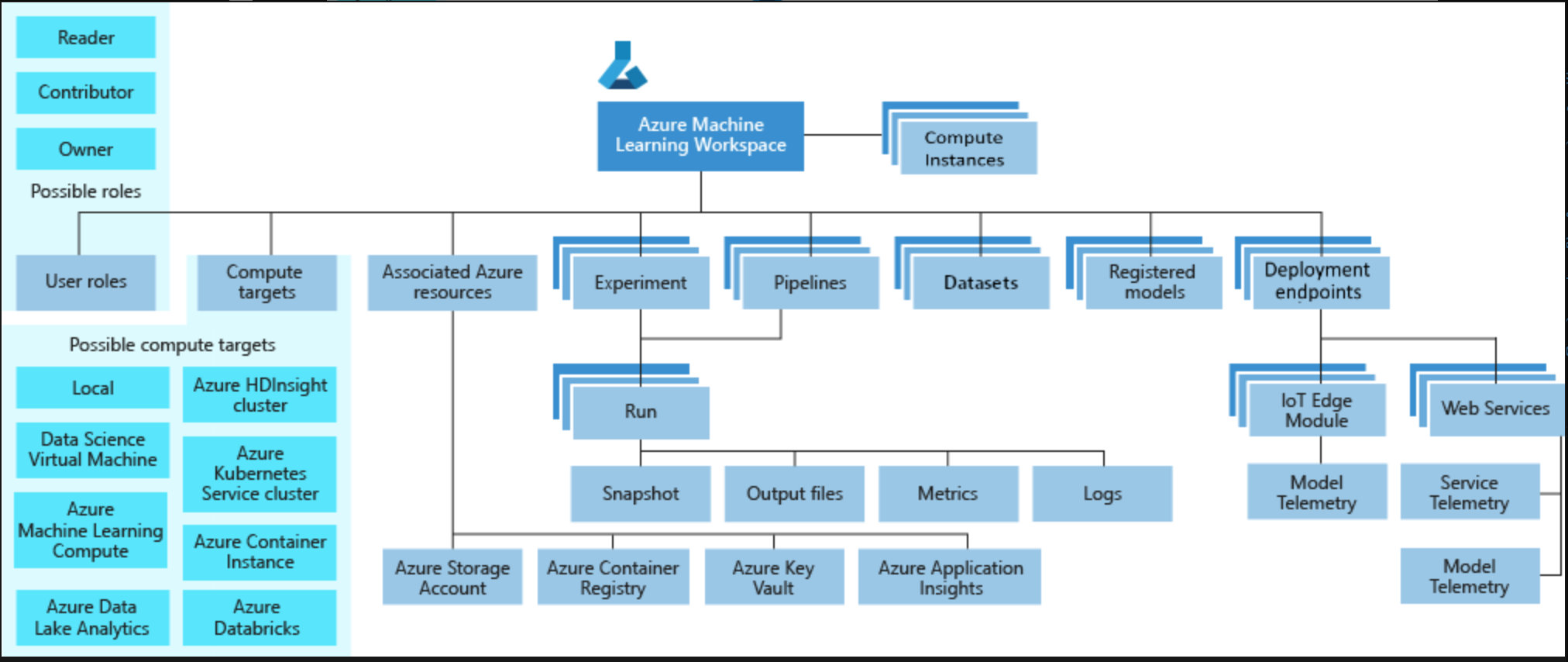
 An AML workspace integrates a lot of different machine learning functionality (image from Microsoft)
An AML workspace integrates a lot of different machine learning functionality (image from Microsoft)As we began the project, the first question was “Which model should we use?” I’ve never participated in a scientific field that is moving as fast as AI is. It is nearly a full-time job just to stay up to date with research. So I read a pile of papers and settled on TridentNet, a recent variant of a model called Detectron2 that was created by Facebook Research. I figured it would be yesterday’s news soon enough, but it seemed to have the right balance between achieving state-of-the-art results and being mature enough to make deployment possible.
Microsoft’s cloud computing architecture, Azure, like Amazon’s AWS or the Google Cloud, has a huge variety of offerings aimed at everyone from individuals to the multinational companies that are the world’s heaviest data users. The AI4E program was very helpful in getting me oriented to Azure’s machine learning offerings. The lessons I learned were:
nbdev requires you to work in a git repository that is set up with a special template, and getting used to its workflow requires a signficant mind shift. The best general editor (really more of an IDE) that I’ve found is Microsoft’s Visual Studio Code. It can be used on your local machine and also can connect to a remote headless VM. Supposedly, it can even be used to debug code running in a container that is running on a remote VM, but I haven’t tried the latter (many dense and forbidding pages of instructions in Azure). At a minimum, it’s a good way to explore code.azureml-sdk) and even more work to get comfortable with building a containerized Docker environment, but it paid dividends when I needed to scale up for heavy training or inference. AML was brand new and very buggy when I started, but it has since settled down. The documentation is good. The 05_aml_pipeline.ipynb notebook shows how I used it, and the Dockerfile I built is at trident_project/docker_files in the repository.
An AML workspace integrates a lot of different machine learning functionality (image from Microsoft)
As I built one VM after another and switched back and forth between accounts, I started realizing that I had a seriously tangled mess of code to keep track of. My primary need was to keep the versions of code in sync between all of the machines I worked on, which included a laptop and 3 or 4 remote VMs on different accounts. Working with collaborators was a secondary concern. I fell back on git and Github, the world standard. Git is superb but it is not simple; as someone once said, you never really stop learning how to use it. My solution was to create a private Github repository for keeping my own mess straight, sync it with each of the remote machines, and then push a clean master copy from that repository to another repository that I shared with Howard. It’s been a great system, but I have to remember to always pull from the central repository before beginning work on a new machine, and to push to it before shutting down a machine.
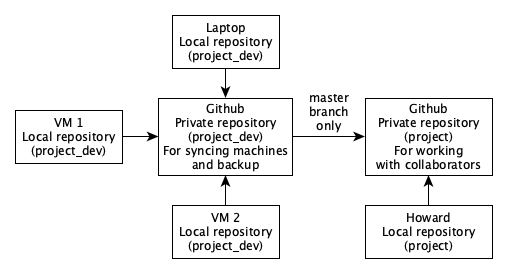 My git workflow
My git workflow